While there is an inordinate amount of wonderful content to be consumed on the internet (my addiction is
HackerNews), every once in a while I get to read a legendary post that simply allows me to level up as a
person. This is a curated list of such articles (soft limit 100):
-
Visual design rules you can safely follow every time,
tldr:
- Use near-black and near-white instead of pure black and white.
- Saturate your neutrals, e.g. very light red instead of grey.
- Use high contrast for important elements: e.g. buttons should be high contrast whereas a divider does not.
- Everything in your design should be deliberate: whitespace, alignment, shadows.
- Optical alignment is often better than mathematical alignment.
- Lower letter spacing and line height with larger text. Raise them with smaller text.
- Container borders should contrast with both the container and the background.
- Everything should be aligned with something else.
- Colours in a palette should have distinct brightness values.
- If you saturate your neutrals you should use warm or cool colours, not both, e.g. warm background with a cool foreground.
- Measurements should be mathematically related.
- Elements should go in order of visual weight.
- If you use a horizontal grid, use 12 columns.
- Spacing should go between points of high contrast.
- Closer elements should be lighter.
- Make drop shadow blur values double their distance values.
- Put simple on complex or complex on simple.
- Keep container colours within brightness limits.
- Keep container colours within brightness limits.
- Make outer padding the same or more than inner padding.
- Keep body text at 16px or above.
- Use a line length around 70 characters.
- Make horizontal padding twice the vertical padding in buttons.
- Use two typefaces at most.
-
What's in a Good Error Message?,
tldr:
- Context: What led to the error? What was the code trying to do when it failed?
- The error itself: What exactly failed?
- Mitigation: What needs to be done in order to overcome the error?
-
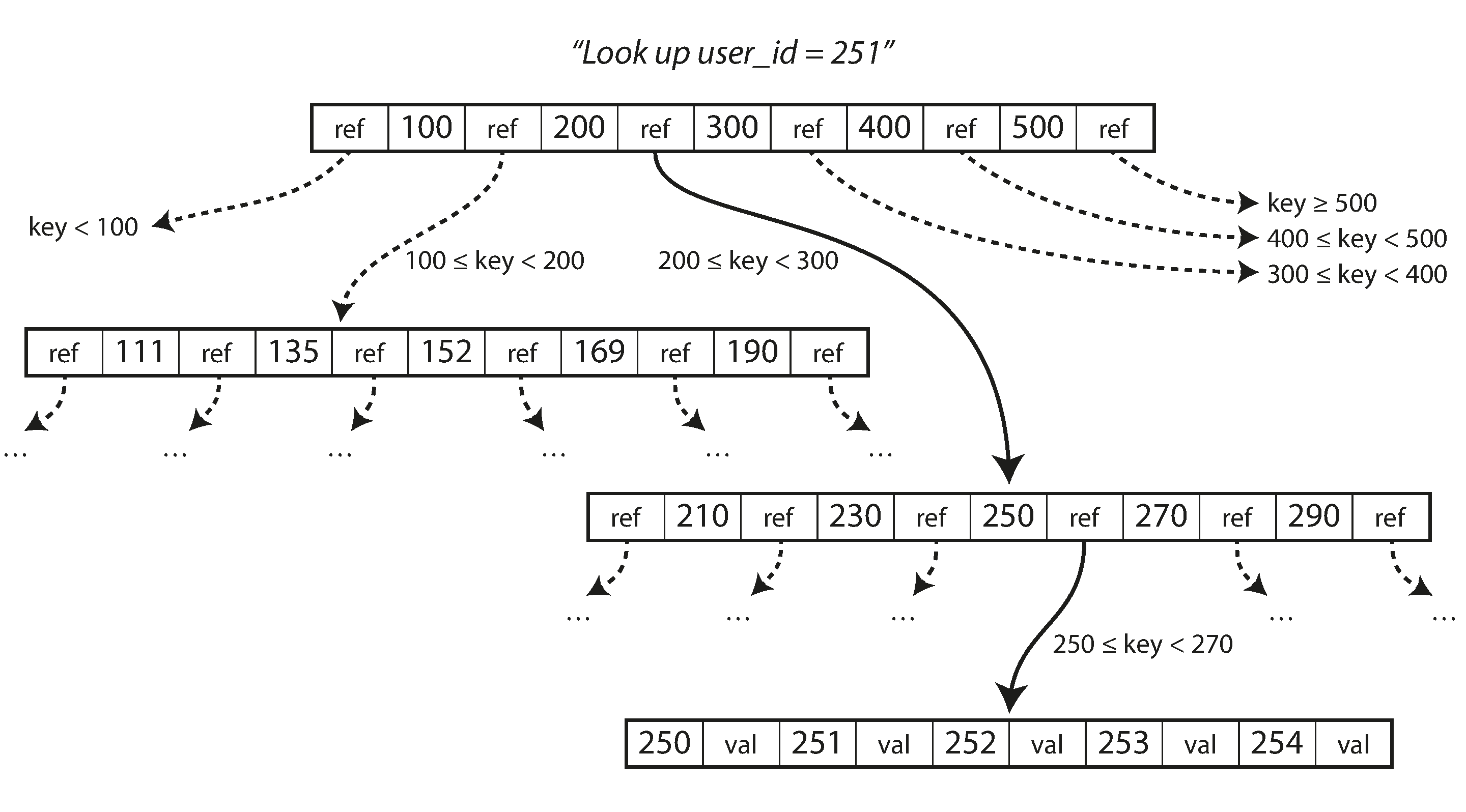
B+ trees
and why they make for excellent data structures in databases, due to the fact that disk I/O is a
significant factor for db performance and the fact that both HDDs and SSDs have hardware constraints that
make the smallest I/O a block, laying out all the keys so that they fit within a
block
results in the best db performance. This can be achieved with slotted pages, separator key truncation and
sibling pointers.
-
Why bitcoin sucks:
high transaction costs and extremely energy inefficient. Moreover, the pseudonymity of it all is
being compromised by blockchain analysis.
-
Centering in CSS,
-
Great for macro layouts containing paragraphs and headlines, prototypes, or generally things that
need legible centering:
.content-center {
display: grid;
place-content: center;
gap: 1ch;
}
-
Great for micro and macro layouts:
.gentle-flex {
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
gap: 1ch;
}
-
Good for phrase-centric centering, tags, pills, buttons, chips, and more:
.fluffy-center {
padding: 10ch;
}
-
Write code, not to
much, mostly functions, self explanatory.
-
Forcing Functions
in Software Development, to find issues with your app/project before you are forced to deal with
them, do the following:
- Use old hardware to run your app, performance issues will become obvious.
-
Delete project from your machine and set it up again, gaps in the setup documentation will be
exposed.
- Add support for a different database, leaky db abstrations will be exposed.
- Add support for a different platform and plaform agnostic abstrations will be exposed.
- Release frequently to find issues with the release process.
-
Let users use your product without knowing anything about it and gaps in UX will immediately show
up!
-
What do executives do, anyway?, the job of an executive
is: to define and enforce culture and values for their whole organization, and to ratify good decisions.
Values are not merely platitudes but something tangible like "tell the truth, even when it
hurts." or "deliver the software on schedule, even if there are bugs."
-
Network
Protocols, a deep dive into the current networking stack including looking at the electronics behind
the current
ethernet frame size of 1500 bytes!
-
Ownership,
References &
Borrowing
and Lifetimes in Rust:
-
Rust ensures that there is exactly one binding to any given resource. This is important as object
handles which refer to the same object in memory could potentially be out of sync due to multiple
threads operating on it. Such move sematics also apply to objects passed via functions.
-
In order to operate on data via functions, Rust provides references which are immutable and allow
only reading data. Rust also provides a mutable reference but there can only be 1 mutable reference
to any particular object or 1 (or more) immutable references to it. This is in order to prevent race
conditions where 2 threads can write to a single resource. Moreover, any reference may not outlast
the scope of the original object. Again, this is in order to prevent any dangling references.
-
Rust provides a way to explicitly declare the lifetime of a reference so that it can never lead to
invalid behaviour like in the case when a reference to a resource is lent out but then deallocated,
leading to the 3rd party holding an illegal reference of which they are not aware.
-
3 tribes of Computer Science, a great article that puts
programmers into 3 camps:
-
Programmers who think in terms of mathematics and keeping code short and beautiful. Examples include
language wonks and functional programming champions.
-
Programmers who write code as close to the machine as possible for maximum efficiency. Examples
include hardware hackers and non-gc language proponents.
-
Programmers who just want to create solutions for others to use. This includes the majority of the
profession.
-
How to build good software, an
amazing article that identifies root causes of poorly produced software and illustrates some key steps
in getting it right. Finally, the article also expounds on 10x engineers and how they simple make better
decisions and automate things which enable other members along with freeing up mental resources for
higher order problems.
On software issues:
- Reusing good software is easy; it is what allows you to build good things quickly;
-
Software is limited not by the amount of resources put into building it, but by how complex it can
get before it breaks down; and
-
The main value in software is not the code produced, but the knowledge accumulated by the people who
produced it.
On getting it done right:
- Start as simple as possible;
- Seek out problems and iterate; and
- Hire the best engineers you can.
-
Operating a
high-scale distributed system, A great overview of experience gained in operating a distributed
sytem. Covers monitoring, on-call
and anomaly detection, outages, postmortems, failover drills, SLAs. Includes tips on blameless
postmortems and asking questions to dig down to the root cause of the issue, e.g. a bug appeared in the
code because it could not be unit tested due to the fact that the system does not support test accounts.
Also, a very important point is never try to fix code in production - always rollback and go through the
normal review process.
-
A
primer on how concurrency safety is handled in different languages, a look at functional languages
and immutability, Rust's borrow checker, behaviours in Pony and the
actor model used in Dart/Erlang.
-
Technical debt is
not a debt, but an unhedged call option, as long as you acknowledge that you are taking on debt, it
may make sense to take it on, e.g.
shipping a product earlier with debt laden code will lead to a better ROI with which one could hire more
resources to "repay" the debt. Note that this needs to be a very conscious decision with a fixed plan.
Also, something to keep in mind - "If it ain't broke, don't fix it".
-
System design - job scheduler, a very
neat article on how to design an event processing engine in a high fault environment. Use a write heavy
database to segment jobs and a co-ordinating service to execute the jobs. The database itself consists
of simple
job and job_state_transition tables.
-
What is functional
programming all about, the core of Functional Programming is thinking about data-flow rather than
control-flow.
-
Web design in 4 minutes, a very very basic css
styling walkthrough!
-
React
16 migration engineering, brilliant take on migration engineering, illustrates the use of:
- feature toggles to reduce merge conflicts
- TDD for api coverage
- regression logging for faster feedback loop
- coverage chart for motivation
- staggered rollout and A/B testing with an eye on product metrics for migration issues
-
The Earth is flat, the
scientific method has been tremendously successful in explaining the workings of our world. It led to
exponential expansion of science and technology that started in the 19th century and continues to this
day. We are so used to its successes that we are betting the future of humanity on it. Usually when
somebody attacks the scientific method, they are coming from the background of obscurantism. Such
attacks are easily rebuffed or dismissed. What I’m arguing is that science is not a property of the
Universe, but rather a construct of our limited brains. We have developed some very sophisticated tools
to create models of the Universe based on the principle of composition. Mathematics is the study of
various ways of composing things and physics is applied composition. There is no guarantee, however,
that the Universe is decomposable. Assuming that would be tantamount to postulating that its structure
revolves around human brains, just like we used to believe that the Universe revolves around Earth.
-
Love your bugs, some really interesting
bugs and the attitude + mindset required for effective bugfixing.
-
Why don't software
development methodologies work?, Essentially, the secret to a team's success is a shared vision and
effective communication.
Methodologies are rather pointless if the previous does not hold true.
-
Things you should
never do - Joel Spolsky, never re-write anything from "scratch", code does not rust, you will be
thowing away a lot domain
knowledge and bug fixes - try to incrementally refactor the codebase
-
Strategy Letter V - Joel
Spolsky, Micro economics 101, try to commoditize your products complement so that the demand for
your product
goes up:
- Microsoft makes a free browser so that more people by it's operating system,
-
Google makes software so that more people rely on it to feed it information which it can use for
better search results which leads to them getting the lions share of advertising money (this example
was added by me)
- Note that it is easier for software to commoditize hardware than the other way around
-
Floating point visually
explained, In the C language, floats are 32 bits container following the IEEE 754 standard. Their
purpose is to
store and allow operations on approximation of real numbers. The 32 bits are divided in three sections:
- 1 bit S for the sign
- 8 bits E for the exponent
- 23 bits for the mantissa
-
Instead of Exponent, think of a Window between two consecutive power of two integers. Instead of a
Mantissa, think of an Offset within that window. The window tells within which two consecutive
power-of-two the number will be: [0.5,1], [1,2], [2,4], [4,8] and so on (up to [21272127,21282128].
The offset divides the window in 223=8388608223=8388608 buckets. With the window and the offset you
can approximate a number. The window is an excellent mechanism to protect from overflowing. Once you
have reached the maximum in a window (e.g [2,4]), you can "float" it right and represent the number
within the next window (e.g [4,8]). It only costs a little bit of precision since the window becomes
twice as large.
-
Laws of UX:
-
The time to acquire a target is a function of the distance to and size of the target -- Paul Fitts.
E.g. if a function needs to be accessed often and/or quickly, make the button big
-
The time it takes to make a decision increases with the number and complexity of choices -- William
Edmund Hick and Ray Hyman. E.g. only provide choices when a good default does not exist.
-
Users spend most of their time on other sites. This means that users prefer your site to work the
same way as all the other sites they already know -- Jakob Nielsen. E.g. respect the platform’s
conventions and interface guidelines.
-
People will perceive and interpret ambiguous or complex images as the simplest form possible,
because it is the interpretation that requires the least cognitive effort of us -- Law of Prägnanz.
E.g. do not stuff too much detail into a small space.
-
Objects that are near, or proximate to each other, tend to be grouped together -- Law of Proximity.
E.g. put actions that do similar things together.
-
The average person can only keep 7 (plus or minus 2) items in their working memory -- George Miller.
E.g. reduce the number of things your users have to remember.
-
Any task will inflate until all of the available time is spent -- Cyril Northcote Parkinson. E.g.
make tasks short, simple and with set deadlines
-
Users have a propensity to best remember the first and last items in a series -- Serial Position
Effect. E.g. put the important things at the beginning or at the end.
-
Tesler’s Law, also known as The Law of Conservation of Complexity, states that for any system there
is a certain amount of complexity which cannot be reduced. E.g. removing features from your product
may result in users not being able to achieve some goals.
-
The Von Restorff effect, also known as The Isolation Effect, predicts that when multiple similar
objects are present, the one that differs from the rest is most likely to be remembered. E.g. make
the most important thing stand out. Alternatively: If you want to stand out from competition, find a
feature which is always the same and make it different.
-
The 3 stages of failure in Life and Work:
-
Stage 1 is a Failure of Tactics. These are HOW mistakes. They occur when you fail to build robust
systems, forget to measure carefully, and get lazy with the details. A Failure of Tactics is a
failure to execute on a good plan and a clear vision. Fixing a failure of tactics involves recording
your process, measuring your outcomes (the provided example of measuring your progress at the gym
hit home), and finally reviewing and adjusting your tactics.
-
Stage 2 is a Failure of Strategy. These are WHAT mistakes. They occur when you follow a strategy
that fails to deliver the results you want. You can know why you do the things you do and you can
know how to do the work, but still choose the wrong what to make it happen. Fixing a failure of
strategy involves launching it quickly, doing it cheaply and revising it rapidly (startup 101).
-
Stage 3 is a Failure of Vision. These are WHY mistakes. They occur when you don't set a clear
direction for yourself, follow a vision that doesn't fulfill you, or otherwise fail to understand
why you do the things you do. Most importantly (and also something that resonated with me
personally), fixing a failure of vision involves taking stock of your life, determining your
non-negotiable and then navigating criticism!
-
What every programmer absolutely, positively needs to know
about encodings and character sets to work with text, an update to the following article by Joel,
this one goes into details regarding how the code points actually look like in binary:
-
Text is always a sequence of bits which needs to be translated into human readable text using lookup
tables. If the wrong lookup table is used, the wrong character is used.
-
You're never actually directly dealing with "characters" or "text", you're always dealing with bits as
seen through several layers of abstractions. Incorrect results are a sign of one of the abstraction
layers failing.
-
If two systems are talking to each other, they always need to specify what encoding they want to talk
to each other in. The simplest example of this is this website telling your browser that it's encoded
in UTF-8.
-
In this day and age, the standard encoding is UTF-8 since it can encode virtually any character of
interest, is backwards compatible with the de-facto baseline ASCII and is relatively space efficient
for the majority of use cases nonetheless.
- The days of one byte = one character are over and both programmers and programs need to
catch up on this.
-
The
absolute minimum every software developer must know about unicode and character sets - Joel
Spolsky, long story short there is no such thing as plain text. Unicode is a standard that defines
characters
as code points. Initially, there were less than 65,536 characters so it was possible to store each
character using 2 bytes (16 bits). However, once the standard grew, there evolved multiple character
encoding schemes: UTF-8 (where every code point from 0-127 is stored in a single byte. Only code points
128 and above are stored using 2, 3, in fact, up to 6 bytes), UTF-16, UTF-7, UTF-32, Windows-1252 (the
Windows 9x standard for Western European languages), ISO-8859-1, aka Latin-1 (also useful for any
Western European language). Note that the UTF encodings can also potentially have a Byte Order Mark
(BOM) at the start of the string which indicates their endianess. Finally, it really only makes sense to
use UTF-8 as it is the most efficient with higest compatibility :)
-
Advanced web security
topics
Classic
The following is snippets of useful information (condensed from articles similar to the above which didn't
make the cut):
-
That XOR trick, Use XOR to remove duplicates and/or
swap. HN discussion is also very relevant.
-
Simpson's paradox, Trends which
appear in groups of data may disappear or reverse when the groups are combined.
-
DevOps and SQL databases, using an SQL
database is no excuse for not following good DevOps practices - either manage schema versions in code
with auto upgrade and rollback or decouple code from the database so that schema changes can be made
independent of code deployments. Also interesting to note the 5 phases of a live schema change:
-
The running code reads and writes the old schema, selecting just the fields that it needs from the
table or view. This is the original state.
-
Expand: The schema is modified by adding any new fields but not removing any old ones. No code
changes are made. If a rollback is needed, it's painless because the new fields are not being used.
-
Code is modified to use the new schema fields and pushed into production. If a rollback is needed,
it just reverts to phase 2. At this time any data conversion can be done while the system is live.
-
Contract: Code that references the old, now unused, fields is removed and pushed into production. If
a rollback is needed, it just reverts to phase 3.
-
Old, now unused, fields are removed from the schema. In the unlikely event that a rollback is needed
at this point, the database would simply revert to phase 4.
-
The point of
microservices, is being able to deploy and test independently for rapid iteration. The article
itself does not cover
version management however.
-
A road to Common LISP, an
excellent resource on getting started with lisp - basically get SBCL and a couple of books :)
-
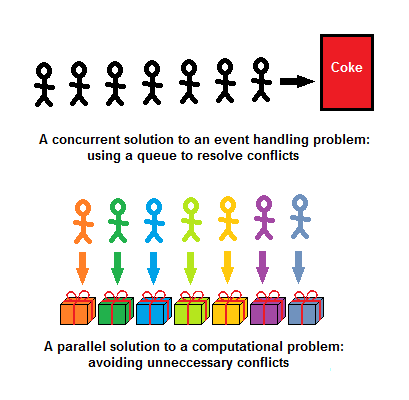
"Concurrency is dealing with inevitable timing-related conflicts, parallelism is avoiding unnecessary
conflicts". A concurrent solution to an event handling problem uses a queue to resolve conflicts whereas
a parallel solution to a computational problem avoids unnecessary conflicts:
Vending machine vs. gifts,
Parallelism and
concurrency need different tools.
-
Wealth is not finite - creation of wealth is independent of the money supply. If you make a gift for
someone using stones arranged in the shape of a heart, you have created something desirable and hence
you are the more wealthier for it.
-
"A good scientist, in other words, does not merely ignore conventional wisdom, but makes a special
effort to break it. Scientists go looking for trouble. This should be the m.o. of any scholar, but
scientists seem much more willing to look under rocks." - Paul Graham
-
The
Log: what every software engineer should know about real-time data's unifying abstraction, use a log
infrastructure like Apache kafka for distributed data consistency - a bit enterprise heavy
but some neat insights.
-
Event-sourcing made
simple, Event sourcing is like git for data. There are generally four components that make a
(minimal) Event
Sourcing system:
- Events: persisted and immutable.
- Aggregates: represent the current state of the application.
- Calculators: read events and update aggregates accordingly.
-
Reactors: react to events as they are created. They trigger side-effects and might create other
events in turn.
-
Stacked diffs vs.
Pull-requests, The basic idea of stacked diffs is that you have a local checkout of the repository
which you can
mangle to your heart's content. The only thing that the world needs to care about is what you want to
push out for review. This means you decide what view of your local checkout the reviewers see. You
present something that can be "landed" on top of master.
The typical workflow is to work right on top of master, committing to master as you go. For each of the
commits, you then use the Phabricator command line tool to create a "Diff" which is the Phabricator
equivalent of a Pull Request. Unlike Pull Requests, Diffs are usually based on exactly one commit and
instead of pushing updates as additional commits, you update the single commit in place and then tell
Phabricator to update the remote view. When a Diff gets reviewed and approaved, you can "land" it onto
remote master. Your local copy and master don't have to be in perfect sync in order to do this. You can
think of this as the remote master cherry-picking the specific commit from your git history.
-
5 mundane Java
performance tricks:
- Size HashMaps whenever possible because resizing them is an expensive process
- Don't iterate over Enum.values() because it creates an expensive array on the fly.
- Use enums instead of constant Strings, especially EnumMap as Enums are more performant.
- Use wrappers for composite HashMap keys, or rather do not concatenate String(s) to make a key as
String hash computations are expensive.
- Stop using JDK8 as the performance of String is much improved in JDK11 and above.
{kind=link}